
LSM树是HBase里非常有创意的一种数据结构,它和传统的B+树不太一样,下面先说说B+树。
1 B+树
相信大家对B+树已经非常的熟悉,比如Oracle的普通索引就是采用B+树的方式,下面是一个B+树的例子:
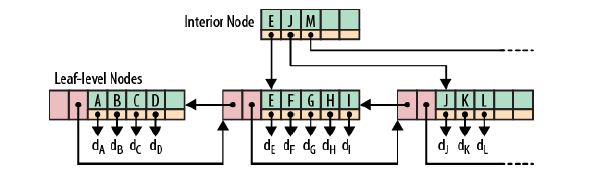
根节点和枝节点很简单,分别记录每个叶子节点的最小值,并用一个指针指向叶子节点。
叶子节点里每个键值都指向真正的数据块(如Oracle里的RowID),每个叶子节点都有前指针和后指针,这是为了做范围查询时,叶子节点间可以直接跳转,从而避免再去回溯至枝和跟节点。
B+树最大的性能问题是会产生大量的随机IO,随着新数据的插入,叶子节点会慢慢分裂,逻辑上连续的叶子节点在物理上往往不连续,甚至分离的很远,但做范围查询时,会产生大量读随机IO。
对于大量的随机写也一样,举一个插入key跨度很大的例子,如7->1000->3->2000 ... 新插入的数据存储在磁盘上相隔很远,会产生大量的随机写IO.
从上面可以看出,低下的磁盘寻道速度严重影响性能(近些年来,磁盘寻道速度的发展几乎处于停滞的状态)。
2 LSM树
为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。
为了更好的说明LSM树的原理,下面举个比较极端的例子:
现在假设有1000个节点的随机key,对于磁盘来说,肯定是把这1000个节点顺序写入磁盘最快,但是这样一来,读就悲剧了,因为key在磁盘中完全无序,每次读取都要全扫描;
那么,为了让读性能尽量高,数据在磁盘中必须得有序,这就是B+树的原理,但是写就悲剧了,因为会产生大量的随机IO,磁盘寻道速度跟不上。
LSM树本质上就是在读写之间取得平衡,和B+树相比,它牺牲了部分读性能,用来大幅提高写性能。
它的原理是把一颗大树拆分成N棵小树, 它首先写入到内存中(内存没有寻道速度的问题,随机写的性能得到大幅提升),在内存中构建一颗有序小树,随着小树越来越大,内存的小树会flush到磁盘上。当读时,由于不知道数据在哪棵小树上,因此必须遍历所有的小树,但在每颗小树内部数据是有序的。
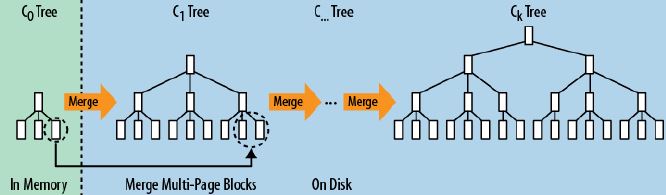
以上就是LSM树最本质的原理,有了原理,再看具体的技术就很简单了。
1)首先说说为什么要有WAL(Write Ahead Log),很简单,因为数据是先写到内存中,如果断电,内存中的数据会丢失,因此为了保护内存中的数据,需要在磁盘上先记录logfile,当内存中的数据flush到磁盘上时,就可以抛弃相应的Logfile。
2)什么是memstore, storefile?很简单,上面说过,LSM树就是一堆小树,在内存中的小树即memstore,每次flush,内存中的memstore变成磁盘上一个新的storefile。
3)为什么会有compact?很简单,随着小树越来越多,读的性能会越来越差,因此需要在适当的时候,对磁盘中的小树进行merge,多棵小树变成一颗大树。